Unicode Character Informer: Documentation
Introduction
Unicode Character Informer is a small utility that displays the codepoint, official description, and Unicode block of any Unicode character that you copy to clipboard. This document describes the basics and the more advanced features of the software.
Every time you copy a single Unicode character to clipboard, it is displayed in the main window. Below the glyph, in a panel at the bottom of the window, the codepoint and official Unicode description are shown. You can copy the text of the bottom panel to clipboard by clicking it.
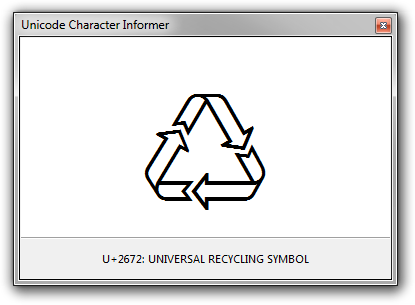
If you press F2, the name of the Unicode block that contains the character is shown in a message box.
If you press F1, you toggle the format of the bottom-panel text between three formats:
U+%s: %s{{tecken|kodpunkt=%s|beskr=%s}}|kodpunkt=%s|beskr=%s
The last two formats are designed to work with the {{tecken}}
template on the Swedish Wiktionary.
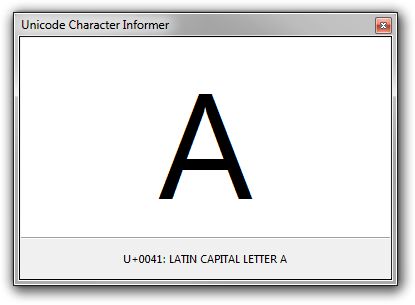
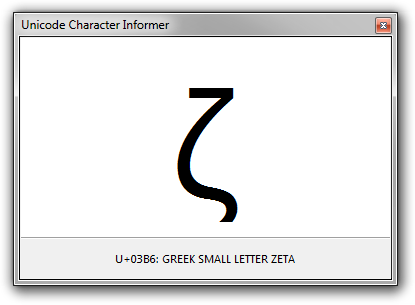
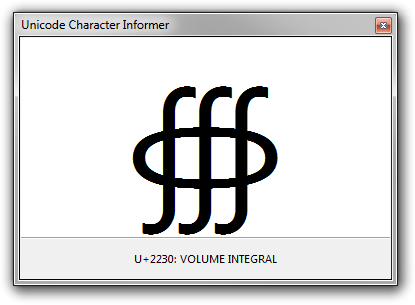
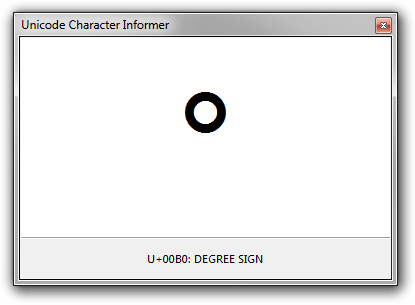
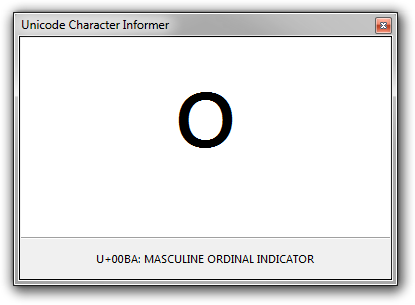
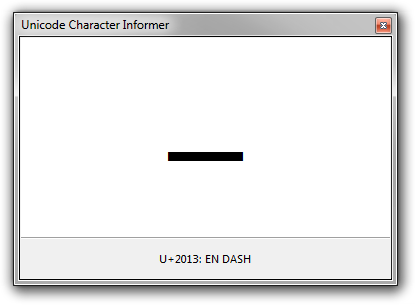
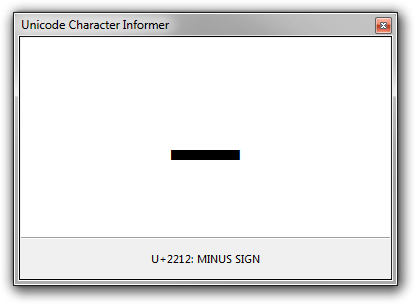
This utility is perhaps most useful when you need to investigate characters that are visually similar:
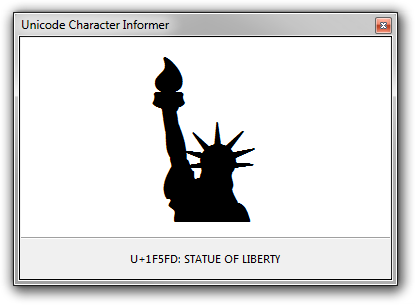
As of version 2.0.0.0 of this software, it supports Unicode characters beyond the Basic Multilingual Plane (BMP), that is, codepoints beyond U+FFFF. Since the Microsoft Windows operating system uses UTF-16 as its internal encoding, this implies that the software supports “surrogate pairs”.
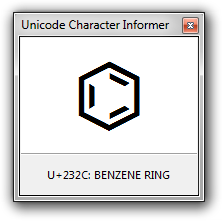
Notice that the window can be resized:
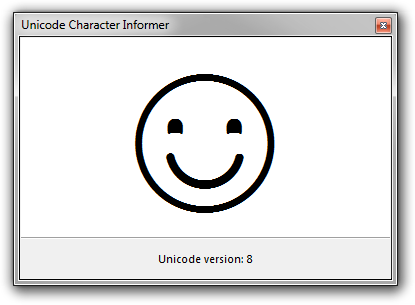
When the application starts, it shows information about the character in the clipboard at that time, if any. If the clipboard doesn’t contain a single Unicode character, a welcome screen is shown instead. You can get back to the welcome screen at any time by pressing F12. The welcome screen displays U+263A: WHITE SMILING FACE and shows the Unicode version of the application’s database.