Gradtecken eller ”masculine ordinal indicator”?
Ett ”språkfel” jag stött på med jämna mellanrum de senaste tio åren är att texter använder º (U+00BA: MASCULINE ORDINAL INDICATOR) när det egentligen skall vara ett gradtecken: ° (U+00B0: DEGREE SIGN), t.ex. när författaren anger en temperatur (t.ex. 37°C) eller en vinkel (90°).
I en del teckensnitt är dessa två tecken visuellt lika, vilket delvis förklarar frekvensen hos missödet. Icke desto mindre är det två helt olika tecken (precis som A och B), så det är fel att använda U+00BA i stället för gradtecknet U+00B0. Läsaren kanske undrar varför detta är fel, om tecknen ändå ser (nästan) likadana ut. En anledning är att de ofta inte ser helt lika ut, så lite tokigt ser det ut. Dessutom, om texten distribueras digitalt, t.ex. som oformaterad text eller i HTML-format, vet man inte vilket teckensnitt som kommer att användas när texten visas för mottagaren, och i en del teckensnitt är dessa två tecken mycket olika (det är ett streck under ringen i U+00BA, se nedan).
Men även om man bortser från det visuella så är det helt fel att använda U+00BA i stället för gradtecknet U+00B0, eftersom tecknen tekniskt är helt olika och har olika betydelse. Sammanblandning får en rad praktiska konsekvenser:
Skärmläsare, som läser upp datorskärmen för t.ex. blinda personer, kommer att uttala texten ”37°C” fel ifall fel tecken används.
Sökfunktioner, t.ex. i texteditor, ordbehandlare eller webbläsare, kommer inte att ge någon träff på den korrekta sökfrasen ”°C” om dokumentet i stället använder MASCULINE ORDINAL INDICATOR (eller, för den delen, tvärtom).
Sökmotorer, t.ex. Google, påverkas på samma sätt.
Datorprogram som försöker läsa texten och extrahera information från den kommer att bli förvirrade. (”Nej, rapporten verkar inte innehålla någon information om föremålets temperatur.”)
Hur ser man då till att använda rätt tecken? Detta beror naturligtvis helt på vilken metod man använder för att infoga specialtecknet. Notera att gradtecknet inte finns på svenska tangentbord.
De flesta använder troligtvis Microsoft Word och dialogrutan Symbol, se skärmbilden nedan.
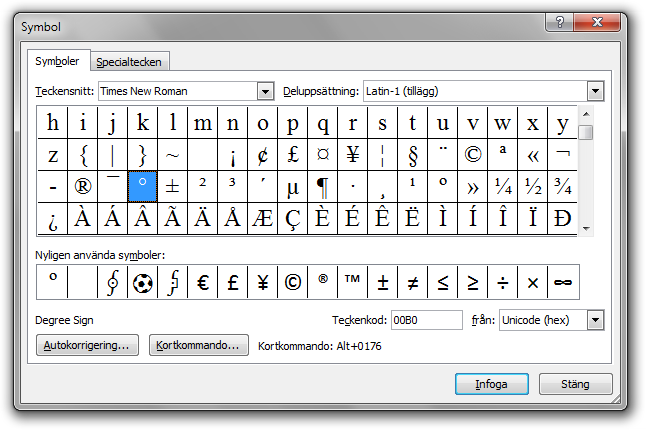
I det här exemplet är gradtecknet markerat. Notera att en beskrivning (”Degree Sign”) av tecknet återfinns i det nedre vänstra hörnet på fliksidan (alldeles ovanför knappen ”Autokorrigering…”). (Dessutom syns koden U+00B0.) Detta gör att vi förstår att det är det riktiga gradtecknet som är markerat.
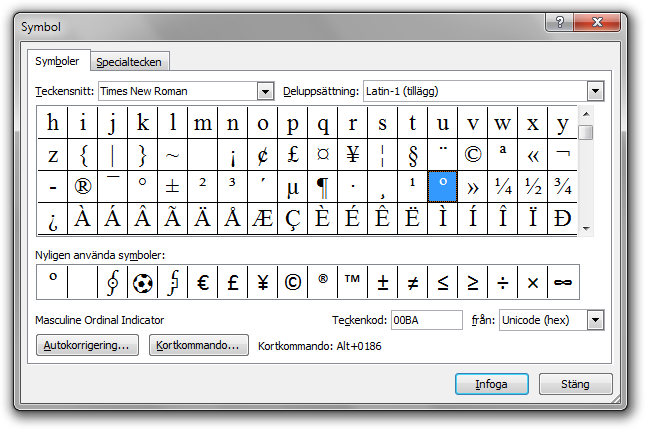
Tio kodpunkter till höger syns U+00BA: MASCULINE ORDINAL INDICATOR. Som synes är tecknet mycket likt gradtecknet. Men om detta tecken markeras inser man av teckenbeskrivningen ”Masculine Ordinal Indicator” (och, om man är en riktig Unicode-nörd, av kodpunkten U+00BA) att detta är fel tecken:
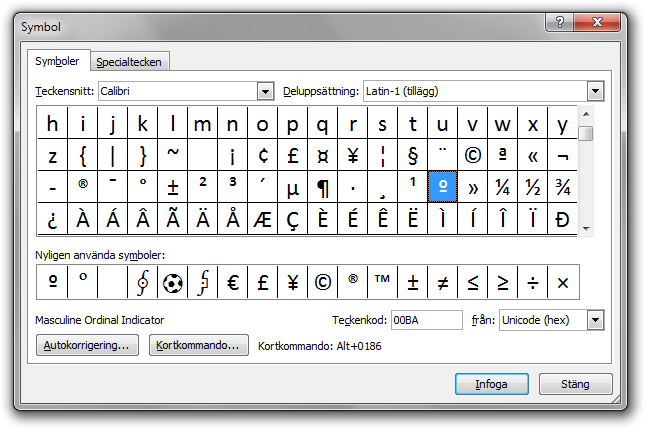
I exemplen ovan används det gamla standardteckensnittet Times New Roman. Om vi byter till det nya standardteckensnittet Calibri ser vi att U+00BA: MASCULINE ORDINAL INDICATOR inte längre liknar gradtecknet: som nämnt ovan ser det senare tecknet lite olika ut i olika teckensnitt. (Fördelen med utseendet i Calibri är förstås att risken för sammanblandning med gradtecknet minskar väsentligt. Frågan är emellertid hur U+00BA, som är mycket ovanligt i Sverige, ”ska” se ut. Förhoppningsvis är båda varianterna korrekta. Själv kan jag inte alls mycket om hur U+00BA används i de språk i vilka tecknet faktiskt används.)
Att infoga specialtecken via dialogen Symbol är mycket omständligt i längden. Om man ofta använder gradtecknet kan man i stället memorera kodpunkten U+00B0. För att infoga detta tecken i Word räcker det med att skriva B0 och sedan trycka på Alt+X.
Ett annat smart tips är att aktivera funktionen ”matematisk autokorrigering utanför matematiska områden”:
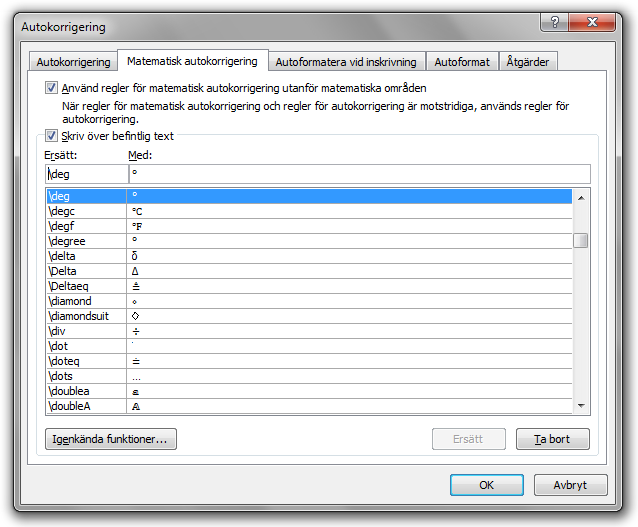
Nu kan gradtecknet infogas med \deg (följt av mellanrum eller skiljetecken). Faktiskt kan med denna inställning alla grekiska bokstäver, matematiska operatorer och matematiska bokstäver infogas med sina koder, även utanför matematiska områden.
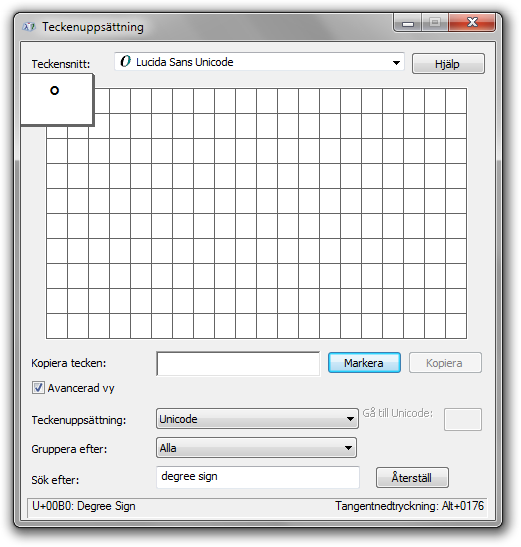
Standardsättet att söka efter och hitta rätt Unicode-tecken i Windows är annars – som läsaren givetvis redan vet – att använda programmet Teckenuppsättning (charmap.exe) som funnits med åtminstone sedan Windows 95:
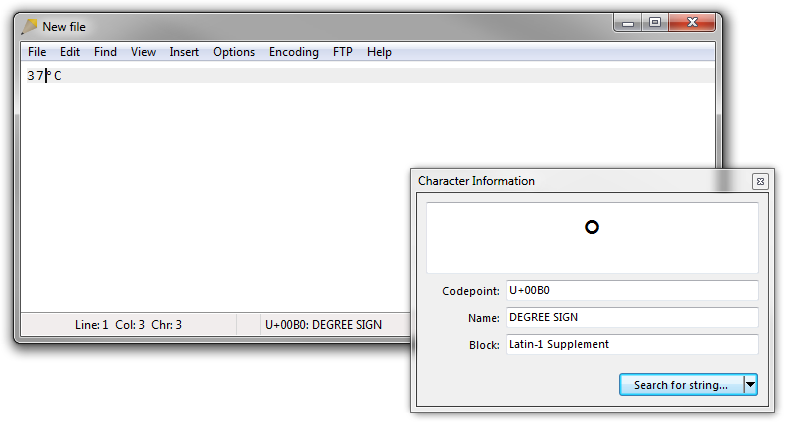
Ett alternativt sätt att både snabbt infoga allmänna Unicode-tecken och erhålla beskrivning och kodpunkt för tecken är att använda en texteditor med stöd för dessa funktioner, t.ex. min egen Rejbrand Text Editor:
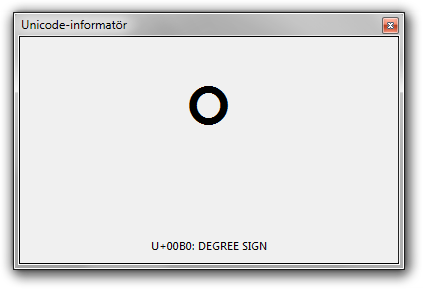
Om man bara är intresserad av att mycket snabbt erhålla beskrivning och kodpunkt för något tecken kan man med fördel använda mitt miniverktyg Unicode-informatör. När programmet körs och ett enskilt Unicode-tecken (f.n. bara i BMP) finns i urklipp visas beskrivning och kodpunkt i programfönstret. (Programmet ändrar informationen varje gång ett nytt tecken hamnar i urklipp.)